2022-2023 | EMAsphere
Taming Chaos
Summary
After several years with the company, I stepped into the CTO role. The team was facing a familiar, escalating challenge: an under-staffed R&D department was struggling to keep up with an unsustainable support load, leading to a massive backlog of ~2000 issues and high stress. Drawing on our collective lessons from past attempts, I designed and implemented a Dual-Track Agile & L2 Support Framework. This new process, fully embraced and executed by the dedicated R&D and Support teams, led to a 50% reduction in our support backlog in the first year and brought it to a stable, manageable level (a few hundred issues) by the second. We successfully restored predictability to our feature roadmap and significantly lowered stress for everyone involved.
The Challenge: A Team Drowning in Support
The R&D team was caught in a difficult position. The product's success and a growing user base, combined with an under-staffed team, had created an unsustainable support load. This was a known issue, and previous attempts to manage it had provided valuable lessons. However, the development-management process was still being bypassed, leading to critical business challenges:
- A Crushing Support Backlog: The team was drowning in ~2000 tickets, unable to make a significant dent, which frustrated both users and internal teams.
- Zero Predictability: Sprints were consistently derailed. We couldn't promise new features to the business or to clients because "urgent" bug fixes constantly stole team-wide focus.
- Constant Interruptions: Developers were context-switching all day. A 5-minute "quick question" on Slack would cost 45 minutes of lost focus, destroying productivity and leading to developer burnout.
- Inter-departmental Friction: The (L1) Support team felt their issues weren't being heard, and the (L2) Development team was frustrated and treated as a "short-order cook" service desk.
There was a clear need for a more robust process and, critically, for a role that could categorize and prioritize issues aggressively, allowing us to efficiently reduce the support backlog while also being productive for evolution features.
The Solution: "Plan the Unplanned"
My core philosophy, built on a lifetime of support experience and the lessons from our past experiments, was simple: We cannot prevent unplanned work, but we can manage it. The goal was to build a "firewall" around the planned Sprint work, allowing the team to focus while providing a fast, reliable, and transparent process for handling the "unplanned."
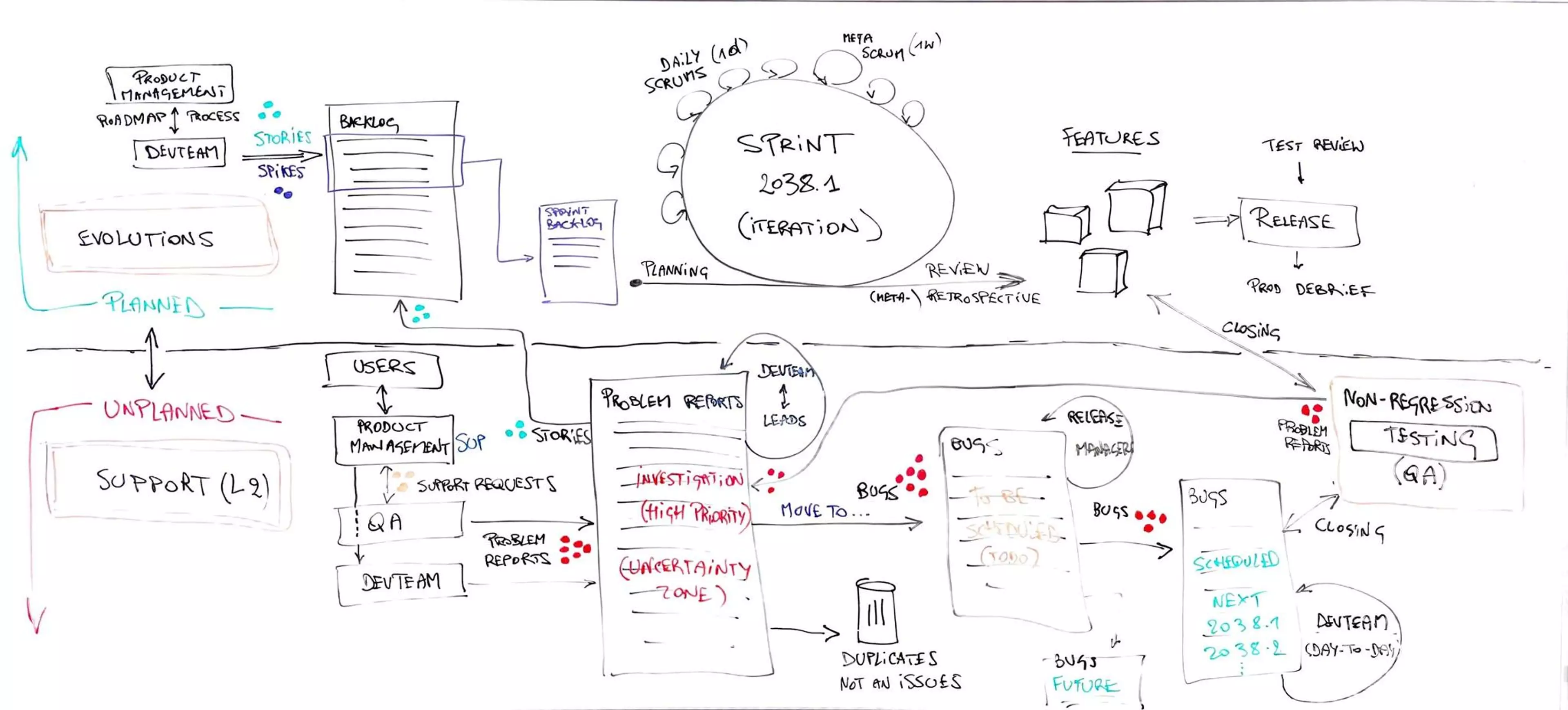
I designed and implemented a Dual-Track Agile Framework, visualized in our original planning sketch:
 Click to enlarge
Click to enlarge
This system operates on two parallel, but interconnected, tracks:
Track 1: The "PLANNED" Stream (Feature Evolution)
This was our standard, Scrum-inspired workflow for new features ("Evolutions"). It was protected, sacred, and focused on delivering the product roadmap.
Track 2: The "UNPLANNED" Stream (L2 Support & Bug Management)
This was the new, formalized process for all incoming requests. It was designed to Investigate, Classify, and Schedule—not to immediately "fix."
Key Components of the New Framework
This was more than a new workflow; it was a new set of rules and roles to enforce a cultural shift from "reactive" to "proactive." The success of this depended entirely on the commitment of the teams to see it through.
Formal "L1 vs. L2" Split
We formally designated L1 Support (Services, Product Mgmt) as the only team to interface with users. The L2 (Development) team was "repelled" from L1 tasks. L2 Support would only accept formally escalated, technical-only issues. While the public process was rigid to break old habits, the teams were encouraged to collaborate closely in practice.
The "No Shadow Support" Rule
All L2 requests were required to be filed as a ticket through formal channels (Jira, email-to-ticket, Slack bot). Direct messages and general Slack channel requests were politely, but firmly, redirected. This was the first step in quantifying the "hidden" workload.
Phase 1: The "Problem Report" (Investigation - Unplanned)
- Definition: An incoming issue was not a "bug." It was an "uncertain issue" called a "Problem Report" (PR).
- Goal: Fast First Response. The goal was twofold: First, to quickly determine what the issue was (bug, limitation, config issue, duplicate). Second, to provide a "fast first response," which was critical for building trust and ensuring the process was perceived as efficient by reporters.
- Strategic Role (Release Manager): I established a "Release Manager" as the gatekeeper. This role managed the "To Be Investigated" backlog and assigned PRs to individual developers. This single point of contact immediately protected the rest of the team from a flood of requests.
- Rollout Plan: We started by assigning this role to the most senior people to establish the process and resist pressure. The long-term plan, which we executed, was to gradually train and rotate new people into the role, decentralizing the capability and maturing the entire team.
Phase 2: The "Bug" (Implementation - Planned)
- The "Golden Rule":"A developer never codes on a Problem Report."
- Process: The only outcome of an investigation was to classify the PR. If it was a confirmed defect, the developer closed the PR and created a new, linked "Bug" ticket.
- Aggressive Scheduling: This new "Bug" ticket landed in a "To Be Scheduled" backlog, owned by the Release Manager. This role now had the authority to:
- Inject: Schedule truly urgent (P0/P1) issues into the current sprint as managed, unplanned work.
- Schedule: Assign all other bugs that could wait to a subsequent, future sprint, treating them as planned work.
The Results: Restored Calm, Predictability, and Trust
This transformation was a true team effort, and its success is a testament to the commitment of everyone involved.
- Massive Backlog Reduction: The teams achieved a 50% reduction in our support backlog in the first year, cutting it from ~2000 issues to ~1000. By the end of the second year, their sustained effort stabilized the backlog to a normal, manageable baseline of a few hundred issues.
- Predictability & Stress Reduction: By formalizing the intake and aggressively prioritizing, we restored predictability. The business could finally rely on our sprint commitments. This, in turn, dramatically lowered the stress level for both the development and L1 support teams.
- Data-Driven Decisions: For the first time, we had a true, data-backed view of our support load. We could see which product areas were generating the most PRs, allowing us to target our efforts on refactoring and technical debt reduction.
- Improved Cross-Team Trust: The L1 Support team was supportive from the beginning, and this process helped them immensely. While they had their own struggles (like mastering a massive and complex product), the new framework gave them a reliable, transparent system. They knew that a "Problem Report" would be investigated immediately (even if the fix was scheduled for later), and a scheduled "Bug" would be fixed reliably. This transparency and predictability rebuilt trust between departments.
Conclusion
A development team, especially an under-staffed one, must treat its focus as its most valuable and fragile resource. This dual-track framework succeeded because the teams involved were committed to making it work. The process itself, built on our collective lessons, provided the necessary structure, but it was their goodwill, hard work, and collaboration that brought it to life. It proves that even when resources are tight, a robust process—one that is strategically rolled out and embraced by the teams—can tame chaos, reduce technical debt, and create a calm, resilient, and highly productive R&D organization.